関節リウマチに対する生物学的製剤の使用は炎症を効率よく改善させるだけでなく,心血管イベントリスクを減少させるかもしれないという系統的レビューです.観察コホート試験と無作為化比較試験を選択したのですが無作為化比較試験では統計的有意ではなかったとのことです.コホート試験では統計的有意な結果が出ましたが出版バイアスの可能性があり,結論を出すには時期尚早と思われます.
Systematic Review and Meta-Analysis: Anti-Tumor Necrosis Factor α Therapy and Cardiovascular Events in Rheumatoid Arthritis
CHERYL BARNABE, BILLIE-JEAN MARTIN, AND WILLIAM A. GHALI
Arthritis Care & Research vol. 63, No. 4, April 2011, pp 522-529
対象
関節リウマチの制御は心血管イベントのリスクを減弱させているかもしれない.我々は抗TNF-α 治療と心血管イベント発症率との間の相関を系統的に評価しようとした.
方法
観察コホートと無作為化比較試験のうち,抗 TNF-α 治療と伝統的な DMARDs 治療法とを比較したリウマチ患者で心血管イベント(全イベント,心筋梗塞,うっ血性心不全,脳血管疾患)について記載のあるものを PubMed および EMBase およびカンファレンスの要約から同定した.相対危険度またはハザード比とその 95% 信頼区間を抽出した.インシデントが報告された場合は罹患密度とその分散を計算するために付加情報も抽出した.
結果
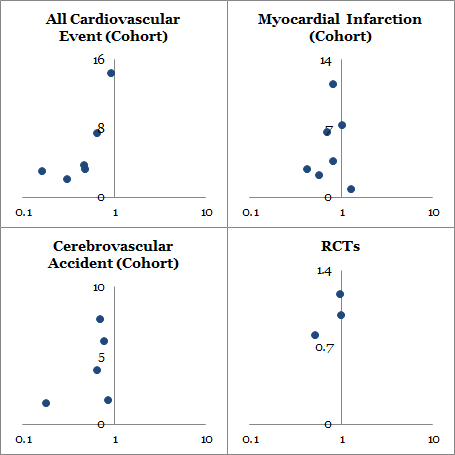
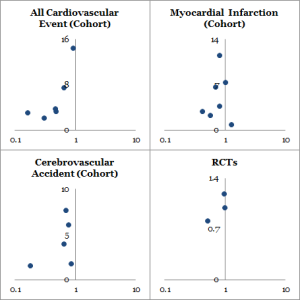
系統的レビューとメタ解析はそれぞれ 16 編と 11 編が含まれた.コホート試験においては抗 TNF-α 治療は全血管イベントの相対危険度と相関しており,調整後の相対危険度と 95% 信頼区間はそれぞれ 0.46 (0.28-0.77) であった.心筋梗塞については 0.81 (0.68- 0.96) であった.また脳血管疾患については 0.69 (0.53 -0.89) であった.無作為化比較試験のメタ解析では心血管イベントのリスクの低下を示唆する点推定値が得られたが,統計的有意ではなかった(相対危険度 0.85,95% 信頼区間 0.28-2.5).
結論
観察研究における抗 TNF-α 治療は全心血管イベント,心筋梗塞,脳血管障害のリスク低下と相関している.コホート試験と出版バイアスとの間には異質性がある.無作為化比較試験での点推定値は 95% 信頼区間で力不足であり,心血管イベントは secondary outcome であったが,無作為化比較試験はリスクを減少させる傾向にあることを証明した.
導入
関節リウマチは慢性炎症性疾患であり,心血管イベント発症リスクの増加と関連している (1-3).このことは伝統的な心血管リスク因子と不適切に治療された関節リウマチの炎症性環境 (4との両者に寄与している.過去 15 年間で関節リウマチに対する治療戦略は劇的に変化しており,DMARDs と生物学的製剤によって早期に寛解達成することが治療目標となった.関節リウマチ患者における心血管リスク因子が注目されるようになったのは,この集団における心血管死亡率と罹患率の上昇が広く認識されるようになったことによる.
リウマチの疾患活動性を適切に維持することで炎症を有効に治療することは心血管イベントのリスクを減少させるかもしれない.最近の系統的レビューによると,メソトレキセートが心血管イベントリスクに対して有効であると明らかになった (5).抗 TNF α 治療はメソトレキセートや他の標準的 DMARDs が失敗した患者にとって切り札となる治療法である.抗 TNF α 治療が付加的にリスクを抑止することは明らかで,心血管疾患の代理マーカーに良い意味でのインパクトを有することが証明されたように.以下の点が明らかになった,例えば循環血中の CRP や IL-6 など.他の内皮機能測定値のうち,頸動脈内膜肥厚と flow mediated dilatation を改善させる (6-7).
治療されたリウマチ患者の大規模コホートの組立は特異的な治療法の転機を評価する機会を国際的に与えており,同時に副作用の情報をも提供している.抗 TNF α 治療の転帰と副作用に関する有意な量のエビデンスは無作為化比較試験により蓄積される.我々はどんな可能性でも抗 TNF α 治療の心血管イベントリスクに関する臨床効果を定義するため,エビデンスのこれらの2つのソース,つまりコホート試験と無作為化比較試験とを系統的にレビューしたかった.特に,我々の疑問は次のようなものであった,リウマチ患者における抗 TNF α 治療と DMARDs 治療とを比較して心血管イベントリスクは観察コホートと無作為化比較試験とで同定されるか否かを試驗しているかである.
対象と方法
系統的レビューとメタ解析は Preferred Reporting Themes for Systemic Revs ad Meta Analysis Group ガイドラインで概説されたフレームワークに従って実施され,報告における標準化と品質を向上させた (8).レビューのプロトコールは文献検索の前に開発された(著者の連絡先から可能な検索).
データソースとリサーチ
我々は PubMed (1950 – 2009/11/1) および EMBase (1980 – 2009/11/1) の系統的文献検索を実施した.関連する記述のレビュー原著および参考文献リストの鍵となる原著はさらに関連出版物から検索した.最近出版された専門家についてはどんな出版されていないデータについても接触して同定した.2007 年から 2009 年のリウマチ及び心臓病学会 (European League Against Rheumatism, Ameican College of Rheumatology, Canadian Rheumatology Association,American College of Cardiology, American Heart Canadian Cardiovascular Society) の年次総会の会議抄録もレビューした.詳細な明細や統計解析において付加的な情報が要求されるインスタンス内で対応する筆者に直接接触した.タイトルや抄録で使われるキーワードや同義語を使用するにあたり,また医療対象者の見出しに使用するにあたり,3つのテーマが創造された.それらのテーマは『関節リウマチ』『心血管イベント』『抗 TNF α 治療』であった.これらの3つのテーマは抗 TNF α 治療を受けているリウマチ患者に発生する心血管イベント報告した研究を同定するため,ブール演算子の AND により結合して用いられた.加えて,『抗 TNF 治療』『関節 リウマチ』のテーマは結合され,我々はCochrane共同計画無作為化比較試験のフィルターを適用し,関節リウマチ患者で抗 TNF α 治療を受けている無作為化比較試験を同定した (9).
試験の選択
2 名の著者 (CB and B-JM) は独立して原著をスクリーニングして全文レビューした.全タイトルと要約を先述の検索方法で取得してスクリーニングした.言語に制約は設けなかった.原著にリウマチ患者が抗 TNF α 治療を受け,心血管イベントをも報告している報告があれば含めた.我々の焦点が臨床的イベントに置かれていたため,動脈硬化の代理マーカーのみを報告しているものは除外した.最初のスクリーニングにおける賛同は 99.7 % であった.どんな原著であれ最初のスクリーニングで2名のいずれかの筆者により研究質問にとって陽性の関連を有しているとして同定されたものは全文レビューした.
次のステップとして全文レビューに着手した.この段階では2つの研究デザインを考慮した.つまり観察コホート試験と無作為化比較試験である.リウマチ患者が抗 TNF α 治療と DMARDs と比較した治療を受け,心血管イベント(心筋梗塞,うっ血性心不全,脳血管障害)について言及したオリジナルのデータを報告していれば,原著には系統的レビューも含まれた.我々は観察期間が 26 週未満の報告は除外した.いかなる同定された有効性も確実らしいということと,短い治療期間における変化でないと保証するためである.第2段階で観察された合意は 95.9 % であった.2名の筆者間での食い違いは3人目の筆者 (WG) を交えた協議によって解決した.定量的メタ解析に含まれた研究は,同等の2群間での相対危険度の定義を可能にするための十分なデータを有していなければならないとされた.
データ抽出と品質評価
データは両著者によって独立に抽出した.我々は患者の人口動態,場所の調査,観察期間を記録した.比較治療(メソトレキセートや DMARDs),リウマチの疾患活動性因子,心血管リスク因子または既存の条件も記録した.相対危険度またはハザード比および関連する 95% 信頼区間は直接抽出した.インシデントが報告された際には,罹患密度とその分散を計算するために両群でのイベント数と患者-年のフォローアップもまた抽出した.回帰モデルにおいて調整共変量が作成された場合にはデータ抽出の際に最も調整された相対危険度と同等のものを選択した.抗 TNF α 治療群と一般的リウマチ治療群との比較においては一般治療群が特定されない状況では DMARDs 治療を受けていると仮定した.研究品質を評価するのに必要な情報は Egger らによる観察コホート試験と無作為化比較試験のためのチェックリストに従い抽出した (10).
データ合成と統計解析
関連性の尺度を計算するための十分なデータを公表していない研究はオリジナルの出版として公表された.彼らが同じ転帰を報告したとしても,我々は2つの研究デザインを1つにまとめなかった.というのは,メタ解析に十分な情報を持つコホート試験のために我々は,各々の転帰のための独立した解析における全心血管イベント,心筋梗塞,脳血管障害,うっ血性心不全の調整済み相対危険度を定義したからである.ハザード比と罹患密度比は直接相対危険度として考慮される.オッズ比として表現される結果は Zhang と Yu により記述された方法 (11) で相対危険度に変換された.メタ解析に十分な情報を持つ無作為化比較試験のため,抗 TNF α 治療群と対照群との間のイベントの相対危険度を計算した.我々はメタ解析には Stata (Stata-Corp) バージョン 10.0 を用い,観察研究を横断した対数変換した相対危険度を計算し,『めちゃくちゃな』無作為化比較試験のための相対危険度を指示した.観察コホートのため,我々は DerSimonian and Laird random-effect モデルを採用して全心血管イベントの転帰を評価し,fixed-effect モデルを採用して心筋梗塞と脳血管疾患の転帰を評価した.我々は fixed-effects モデルを採用して無作為化比較試験を評価した.コホート試験と無作為化比較試験の相対危険度および対数相対危険度並びにそれらの 95% 信頼区間を要約するために forest plot 法が開発された.コホート試験における経時的なエビデンス蓄積効果を同定するために, metacum なコマンドが使われた.
研究の間の異質性は Cochrane Q 統計値および I2 統計値を用いて評価した.1つのコホート試験には Yates 変換が適用され,解析を実行した.というのはその研究 (Geborek et al, 12) にはイベントが発生しなかったためである.Begg test および funnel plot による可視化解析は出版バイアスを評価するために用いた.
結果
全部で 5,022 の要約がデータベース検索方法から同定された.付加的な 7 つの出版物は手動での検索および協議の手続きにより同定された.5,029 の要約のうち 97 編が全文レビューに選択された (Figure 1).予め指定しておいた適合基準に基づいて 16 研究が系統的レビューに選択された.それらの研究の特徴を Table 1 に示した.要約すると,我々は 13 のコホート試験(106,202 名の患者)と 3 つの無作為化比較試験(2,126 名の患者)を同定した.イベントは研究によってばらつきがあり,全心血管イベント(5 つのコホート試験および 1 つの無作為化比較試験),心筋梗塞(6 つのコホート試験および 2 つの無作為化比較試験),脳血管疾患(4 つのコホート試験),うっ血性心不全(6 つのコホート試験)を含んでいた.4 つのコホート試験が全ての抗 TNF α 治療法を使用したと報告し,5 つのコホート試験が infliximab および etanercept に特化して報告し,4 つのコホート試験は infliximab, etanercept および adalimumab の使用を報告した.1 つの無作為化比較試験が infliximab, etanercept, adalimumab の使用を報告した.我々の検索には golimumab も含まれていたにもかかわらず,同定された研究にこの薬剤を使用したものはなかった.Table 2 に報告されたリスク測定および観察コホートにおける解析に用いた調整方法および共変量を示した.データ抽出を実施した後にメタ解析に耐えうると同定されたのは,たった 8 編のコホート試験と 3 つの無作為化比較試験だけであった.
研究品質
コホート試験と無作為化比較試験は Egger (10) らによって提案された要素に従って評価された.Table 1 および Table 2 に研究品質を評価するのに要求される情報をまとめて示す.コホート試験の大部分においては患者サンプリングと転帰の評価は,コホート試験デザインにおける固有の限界を,出来るだけ客観的に与えられる.2 編のコホート試験 (Listing et al, 2008 [13], Dixon et al, 2007 [14]) は高品質と考えられ,11 編は中等度の品質とされた.中等度の品質の限界の大部分は,代表とコホートの疾患コースにおける時間ポイントを定義する情報が提供されない欠如である.1 つを除いた全てのコホート試験にとって,コホートに組み入れられた後の治療法は標準化もされず無作為化もされていなかった.現実の観察研究に期待されているように.5 つのコホート試験はベースラインでのリウマチや心血管危険因子について調整しておらず,これらのうち,事前に指定したメタ解析のための適合基準に合致していたのはたった 3 編であった.全ての無作為化比較試験は高品質であり,3 編の研究は盲検化,無作為割付,試験中の患者の流れを透明化する報告といったキー要素を有していた.
コホート試験結果
全心血管イベント,心筋梗塞,脳血管障害を発症した例についての抗 TNF α 治療効果を forest plot を Figure 2 に示す.要約すると,抗 TNF α 治療は全心血管イベント発症のリスク減少と相関し(調整相対危険度は 0.46, 95% 信頼区間は 0.28-0.77),心筋梗塞については (0.81, 95%CI 0.68-0.96),脳血管障害は (0.69, 95%CI 0.53-0.89)であった.これらのエンドポイントの解析によって研究間の異質性が明らかになった.全心血管イベントに対する I2 = 89.3%, (異質確率 P < 0.001), 心筋梗塞については I2 = 39.9% (P = 0.139), 脳血管疾患については I2 = 39.3% (P = 0.176) であった.各々のエンドポイントに対して出版バイアスを解析した.外観検査は Begg’s test が有意な値 (P = 0.05) をもって全ての心血管イベントの出版バイアスを示唆していた.抗 TNF α 治療によって心血管イベントが増えたとする報告は少なかった.funnel plot による心筋梗塞と脳血管疾患は対照的であり,Begg’s test の値はそれぞれ P = 0.851, P = 0.174 であった.各々のエンドポイントについて報告した少数の研究では視覚的かつ統計的な funnel plot の解釈に限界があると報告していた.
全てのコホート試験に対する累積メタ解析が実施され,転帰としての心筋梗塞を報告した研究について経時的な変化が起きるか評価し,この解析によって年余に渡り抗 TNF α 治療との間に有意な変化はないことが明らかになった.
うっ血性心不全を転帰として報告した研究においては利用に足る数が十分でなかったことや,エンドポイントに関して一貫性を欠いた定義,協会の方向性が不確実に去るなどしたため,着手できなかった.我々はそれにもかかわらず,このエンドポイントについて報告した 6 つの研究に関する所見を提供した.Wolfe and Michaud は抗 TNF α 治療を受けた群では DMARDs 治療を受けた群と比較して全心不全イベント罹患率が 1.2 % (95%CI -1.9 – -0.5) 減少することを報告したが,発生例においては有意ではなかった (15).Carmona らは抗 TNF α 曝露群とメソトレキセート曝露群とのうっ血性心不全症例の率比が 0.14 (95%CI 0.06-0.32) であると同定した (16).Listing らのグループはうっ血性心不全発症したのは抗 TNF α 群では 25 名のうち 16 名であり,対してDMARDs でマッチさせた対照群では 25 名中 20 名であったと同定し,相対危険度は 0.8 (95%CI 0.56-1.14) であった (13).一方,Gole らの研究では抗 TNF α 治療群と DMARDs 群との間に心不全発症率に本質的な差異はないと明らかになった(103 名のうち 7 名に対して 100 名に対して 8 名, 相対危険度 0.85, 95%CI 0.32-2.26)(17).他の2つの研究では抗 TNF α 群で心不全のリスクが上昇した.Curtis らは 4.4 倍のリスク上昇を同定し,Setoguchi らは調整ハザード比が 2.1 (95%CI 1.0-4.3) と同定した (18, 19).
無作為化比較試験結果
3 つの無作為化比較試験のメタ解析により,心血管イベント発症率の相対危険度が抗 TNF α 群において DMARDs 群と比較して 0.85 (95%CI 0.28-2.59) であると明らかになった (Figure 3).この 95% 信頼区間はとても広く,コホート試験のメタ解析で見つかった点推定値と 1.0 の両者を包含する.その研究では同質であることが明らかになった (I2 = 0%, P = 0.90).無作為化比較試験の所見からは統計的有意ではないものの,点推定値は効果においてコホート試験と同じ方向を示しており,心血管イベントにおいてはこの無作為化比較試験で差異を評価するには力不足であり,数が少なすぎることを認めざるをえない.
考察
本系統的レビューとメタ解析は例の仮説を支持する,つまり抗 TNF α 製剤による治療はリウマチ患者の全心血管イベント,心筋梗塞,脳血管疾患のリスク減少と相関していると.リウマチ患者の死因において心血管疾患が 35-50% を占めていることから,この所見は大きな潜在的重要性を有している (20).全てのコホート試験が示したように,心血管疾患の転帰にもかかわらず,感度分析後も心血管イベントのリスク減少が証明された.更に,累積解析が証明したように,その効果は年余に渡り安定していた.少数の無作為化比較試験しかこの系統的レビューとメタ解析の適合基準に合致しなかったにもかかわらず,点推定値の方向は統計的有意ではなかったものの,リスクを減少させる方向に一致していた.
コホート試験と無作為化比較試験との所見は一貫性のあるものか,乖離しているか結論付けるべきだろうか?統計的にはそれらは一貫しておらず,それゆえそれらは同じ効果を証明したものと主張される可能性がある.しかしながら,そのコホートの有効性の推定値は有意である一方,無作為化比較試験では有意でない.後者の推定値は 1.0 に近い.Concato らは既に,よくデザインされた観察コホート試験と無作為化比較試験との間の一般的な合同所見の値と関連性について議論している (21).彼らは次のように提案している.そのようなシナリオはよくあることであり,特異的な曝露効果が関心のある転機について結論するための付加的な堅牢性を提供していると.しかしながら,我々は “healthy user effect” の我々の結果への寄与の可能性について考慮すべきだろう (22).関節リウマチの文脈においては “healthy user” は一般に若く健康であり,より積極的な(抗 TNF α 製剤を含む)リウマチ管理のようなヘルスサービスを受ける傾向があり,潜在的に他の心血管因子を修飾する治療を受ける傾向にある.これは次のことを暗示している.つまり,患者間の素材の違いがあり,それは抗 TNF α 治療を受けているかそうでないかの違いであり,無作為化比較試験に対して相対的に(コホート試験においては測定不能な交絡因子はコントロール出来ないため)コホート試験における心血管イベント減少の違いとなると.観察試験と無作為化比較試験との間の効果の差異は,ホルモン補充療法の差ではないかとの議論も起きた (23).しかしホルモン補充療法の記録されたものとは異なり,我々の所見は研究デザインと様々なユーザー層とを超えて一貫していた.抗 TNF α 製剤と心血管イベント発生減少との関連性はヘルスケア分配構造の異なる国家を超えて一貫していた (15, 24).その効果はまた社会経済的階層を超えて一貫しており,メディケイドを受けるような患者でも抗 TNF α 治療で同じ利益を得ているように見えた (19).その効果は年齢を超えて一貫しており,若年患者や高齢患者いずれにおいてもイベント発生を減少させていた (14, 16).最後になるが,我々の累積解析において証明されたように,我々のコホート試験が出版された時期を超えて一貫していた.抗 TNF α 治療がもっと広範囲に処方され,もっと患者集団に拡大することで,我々はその製剤の使用と心血管イベント発生減少との関連を観察し続けた.
我々のレビューは潜在的に心血管イベントリスクを減少させる原因となる機序を同定していない.疾病管理自体を改善させたり炎症パラメーターを改善させたりしてでも,結果として潜在的に心毒性のある薬物,例えば抗炎症性薬物や副腎皮質ホルモンなど,の使用を減少させている.あるいは抗 TNF α 製剤の直接の効果であって,抗 TNF α 製剤による動脈硬化や炎症の代理マーカーの改善を見ているのかもしれないと基礎科学研究の文脈の中で考慮されるべきである.抗 TNF α 治療は CRP の減少と相関しており,CRP は心血管疾患の独立危険因子として知られている (25, 26).強直性脊椎炎や他の炎症性疾患の治療は,3ヶ月間の治療後の脂質組成においてエタネルセプトが考慮すべき改善を証明した (27).血管生物学的研究を通じて Gonzalez-Juanatey とその研究者たちは内皮機能の改善を証明した.それには抗 TNF α を含む生物学的製剤を投与された患者の flow-mediated dilatation または carotid intima-media thickness を測定した (28, 29).European League Against Rheumatism の最近の推奨では炎症性関節炎に対する早期の積極的治療を強調しており,心血管リスクを2つの経路で低下させる目的で抗 TNF α 製剤とメソトレキセートを使用することを推奨している (30).1番目の経路とは抗 TNF α 製剤で炎症を減少させることによる直接効果であり,2番目は関節炎と関節機能を改善することで身体活動性が向上し,その後他の心血管リスク因子,例えば糖尿病や高血圧など,を減少させることになる.
我々の研究には,コホートはそれぞれの治療群に割り付けられ,所定の治療法を受けていると仮定しているという限界がある.DMARDs や何の製剤の治療を受けている患者の割合を考慮した情報が利用できない.我々は次の前提を置くしかなかった,両治療群共に同じく寛解をゴールとして治療を受けていると.我々は抗 TNF α 単独治療群とそれに DMARDs を併用した群とを比較した解析ができなかった.というのはその情報が文献からは提供されなかったためである.メタ回帰分析も出来なかった,重要な併存疾患と心血管リスク因子の情報が限定されていたからである.コホート試験もまた関心のある転帰のモデリングのため統計的に調整を変化させた.コホート試験の結果のメタ解析は限定的で著明に異質であることをも我々は認めた.少なくとも一部では,巨大なサンプルサイズが異質検定には過剰であることを説明しうる.それぞれの研究の効果量の visual inspection は一貫して抗 TNF α 治療でイベントが減少したことを証明しており,故にメタ解析は効果が均一な方向と判断されたと考えられている.
抗 TNF α による無作為化比較試験に関する限界は,抗 TNF α 治療による短期治療効果を第 1 に実施しており,副作用は secondary end point となっていることによる.無作為化比較試験は高度に選択された集団からなり,心血管イベントリスクが低いように見える.無作為化比較試験を我々の研究に含めた利点は,副作用が厳しい基準で判定される点にあり,転帰の提供が確実であることであった.それらはまた抗 TNF α 治療と標準的な DMARDs 治療との効果を直接比較することを可能にした.
我々のレビュー所見についての最後の注意点として,certolizmab が我々の研究では考慮されていないことである.Certolizmab は承認されたばかりであり,我々のレビュー開始時には臨床現場に広がり始めたばかりであり,我々の検索方法には先験的に含まれていなかった.我々の適合基準に合致する certolizmab の研究は1つだけであり (31),この報告には我々のメタ解析にインパクトを与える結果はなかった.
要約すると,我々は次のことを同定した,抗 TNF α 製剤による関節リウマチの治療は心血管イベントリスク減少に関連しているようで,その所見は明らかな生物学的なもっともらしさを支持している.我々は,リウマチにおける抗 TNF α 製剤の利益の更なる観察に努めた,特に無作為化比較試験とコホートの両者においてより長期間観察したものを.より長期間観察すれば,心血管イベント減少効果をより顕著に観察でき,抗 TNF α 治療を現在受けている患者は相対的に若く,数年後に心血管疾患に罹患することはなくなるかも知れない.潜在的な共同設立者がより詳細な情報を提供する研究により,この文献本体により高い価値を付加することになるだろう.



!2!}")

 = S_0(t)^{\exp(R-R_0)}")


 = A \cap \neg B")
 + p\log n")
+2N")
 = \sum_{\alpha=1}^{n}\log f(x_{\alpha}|\theta)")
 , that is maximum likelihood estimator, maximizes l(θ) and this is called as maximum-likelihood method.
, that is maximum likelihood estimator, maximizes l(θ) and this is called as maximum-likelihood method.  = \Sigma_{\alpha=1}^{n}\log f(x_\alpha |\hat\theta)") is called as maximum log-likelihood.
is called as maximum log-likelihood. }{\partial \theta} = 0")
\pm1.96\times\mathrm{SE})\\ \mathrm{SE}=\frac{LN(\mathrm{ES}/\mathrm{95\%LL})}{1.96}=\frac{LN(\mathrm{95\%UL}/\mathrm{ES})}{1.96}")